Motion : Break | Genre : Break

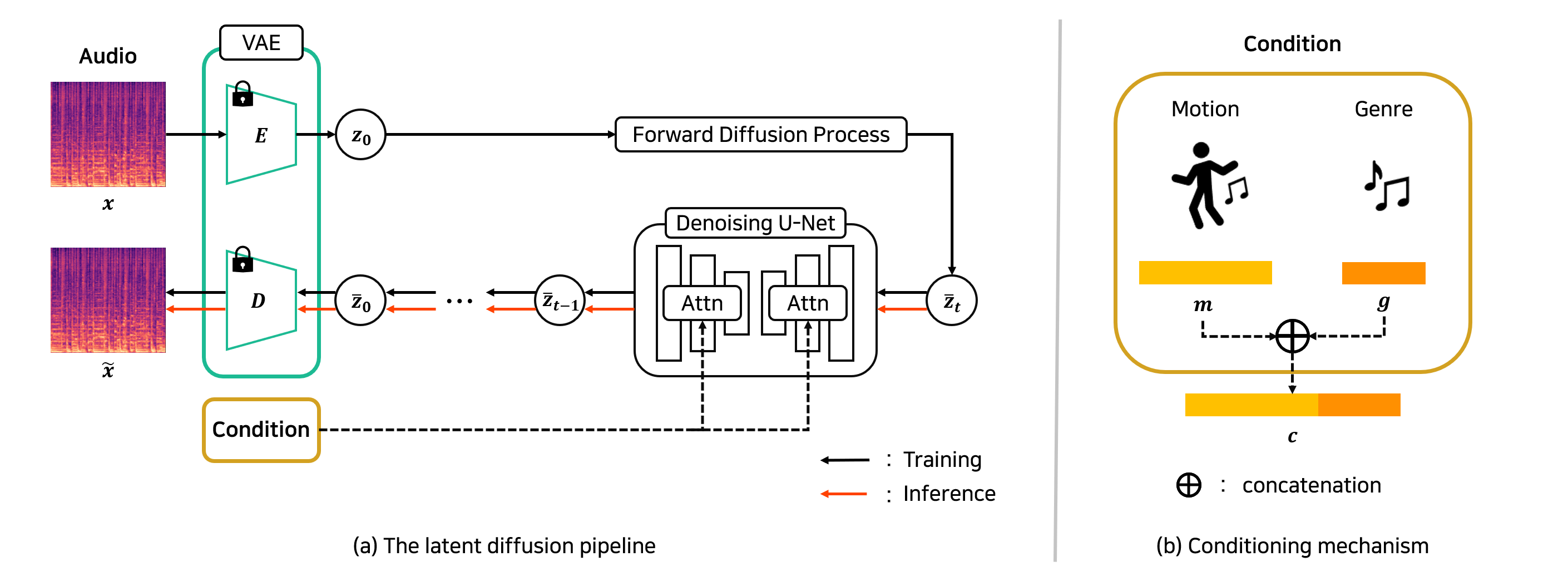
Music's role in games and animation, particularly in dance content, is essential for creating immersive experiences. Although recent studies have made strides in generating dance music from videos, their practicality in integrating music into games and animation remains limited. In this context, we present a method capable of generating plausible dance music from 3D motion data and genre labels. Our approach leverages a combination of a UNET based latent diffusion model and a pre-trained VAE model. To evaluate our model's performance, we employed metrics that assess various audio properties, including beat alignment, audio quality, motion-music correlation, and genre score. Quantitative results show that our approach is better than previous methods. Furthermore, we demonstrated that our model can generate audio that seamlessly fits to in-the-wild motion data. This capability enables us to create plausible dance music that complements the dynamic movements of characters and enhances the overall audiovisual experience in interactive media.
Motion : Break | Genre : Break
Motion : Jazz Ballet | Genre : Jazz Ballet
Motion : House | Genre : House
Motion : Krump | Genre : Krump
Motion : LA Sytle Hip-Hop | Genre : LA Sytle Hip-Hop
Motion : Lock | Genre : Lock
Motion : Break | Genre : Jazz Ballet
Motion : Jazz Ballet | Genre : Break
Motion : House | Genre : LA Style Hip-Hop
Motion : LA Style Hip-Hop | Genre : House
Motion : Gangnam Style | Genre : Pop
Motion : Swing Dance | Genre : Waack
Motion : Fist Fight | Genre : Break
Motion : Shoulder Throw | Genre : Krump
Our method lacks the diversity as it generates similar audio when presented with different motions within the same genre.
Motion : Fist Fight | Genre : Break
Motion : Break | Genre : Break
Our method has difficulty in generating plausible vocals.
Motion : Middle Hip-Hop | Genre : Middle Hip-Hop
Our method struggles to generate relatively long sequences.
Motion : Gangnam Style | Genre : Pop
This work was supported by the National Research Foundation of Korea (MSIT) (No. RS-2023-00222383)
and Korea Creative Content Agency (MSIT)
(Project Name: Development of universal fashion creation platform technology for avatar personality expression, No. RS-2023-00228331) grants funded by the Korea government.
We would like to thank our labmates from the Visual Media Lab (VML) for their support especially the Character team, Chaelin, and Seokhyeon for their invaluable insights.
We would also like to extend our gratitude to Joel Casimiro for his assistance in crafting our preview image.